什么是深度优先遍历
我们从 dom 节点遍历来理解
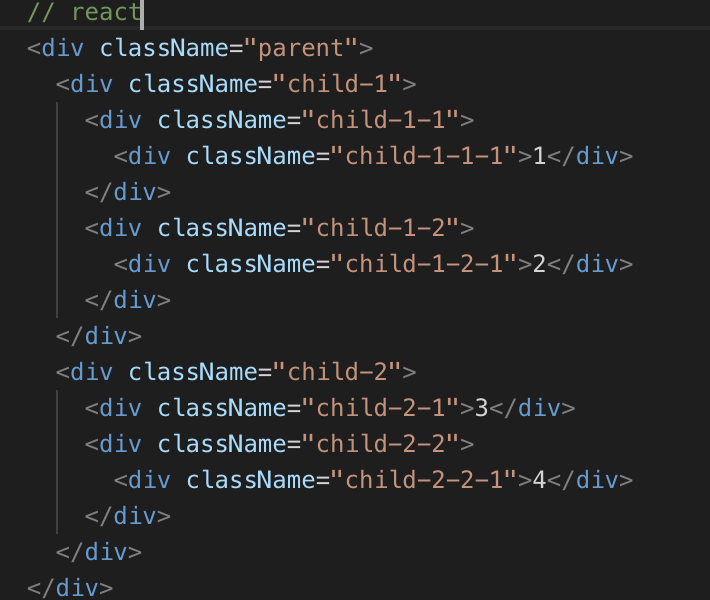
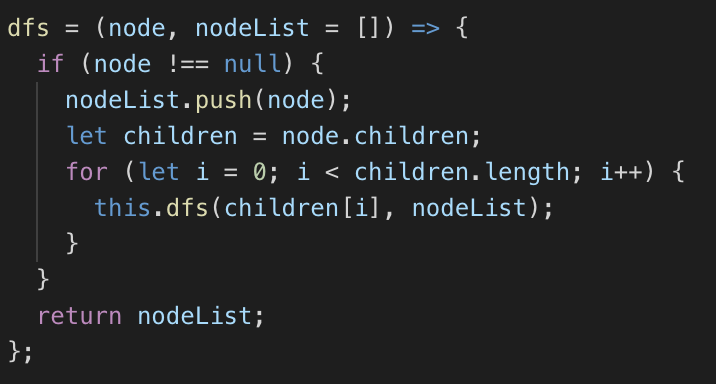 从某个顶点 v 出发,首先访问该顶点然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和 v 有路径相通的顶点都被访问到。若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
结果:
从某个顶点 v 出发,首先访问该顶点然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和 v 有路径相通的顶点都被访问到。若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
结果:

什么是广度优先遍历
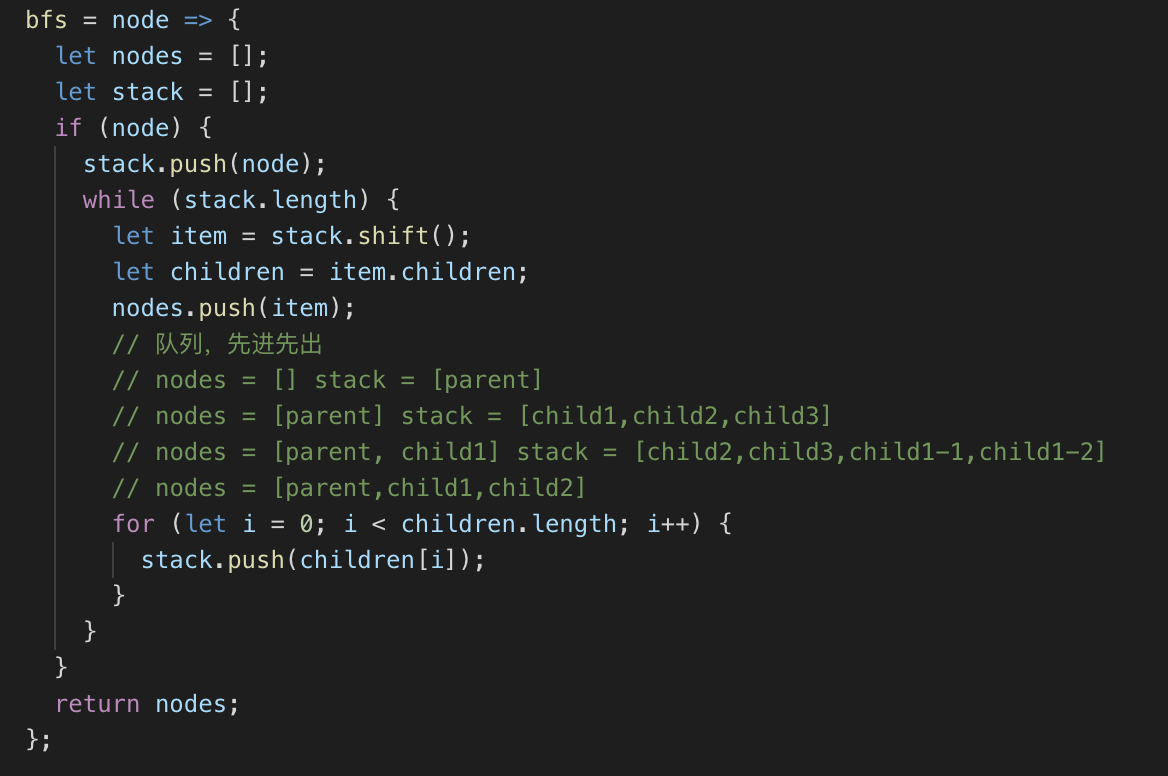
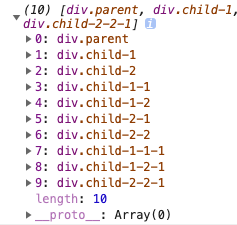
从图中某顶点 v 出发,在访问了 v 之后依次访问 v 的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,直至图中所有已被访问的顶点的邻接点都被访问到。 如果此时图中尚有顶点未被访问,则需要另选一个未曾被访问过的顶点作为新的起始点,重复上述过程,直至图中所有顶点都被访问到为止。
最简单的深拷贝
1 | |
这个深拷贝方法是最简单的,就是利用JSON.stringify将 js 对象序列化(JSON 字符串),再使用JSON.parse来反序列化(还原)js 对象,但是它有它的局限性。
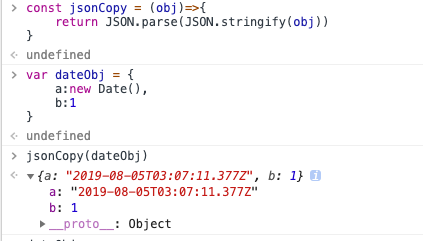
- Date 对象
经过此方法转换之后,Date 对象将会变成字符串
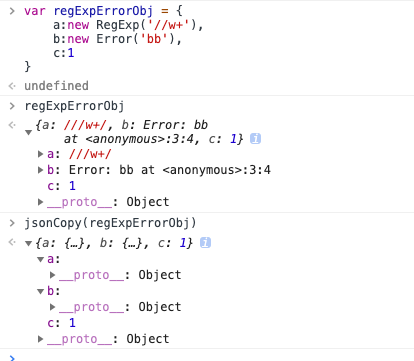
- 如果 obj 里有 RegExp、Error 对象,则序列化的结果将只得到空对象;
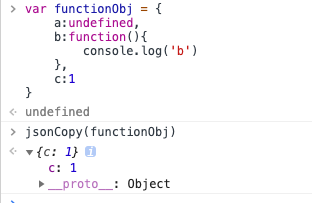
- 如果 obj 里有 undefined,function,会丢失
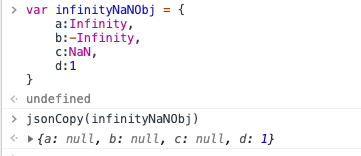
- 如果 obj 里有 infinity,-infinity,NaN,会变成 null
- JSON.stringify()只能序列化对象的可枚举的自有属性,例如 如果 obj 中的对象是有构造函数生成的,则使用 JSON.parse(JSON.stringify(obj))深拷贝后,会丢弃对象的 constructor;
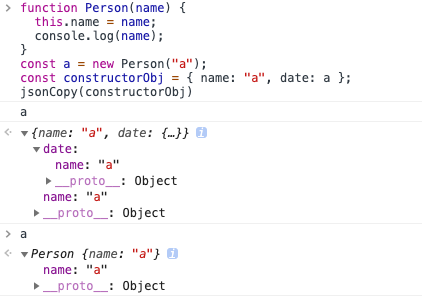
- 如果对象中存在循环引用的情况也无法正确实现深拷贝;